¶ Introduction
L'importance de la haute disponibilité (HA) est devenue cruciale aujourd'hui, notamment avec la dépendance croissante des entreprises aux applications en ligne, aux services numériques et aux plateformes de données. La HA permet d'assurer que ces services restent accessibles et fonctionnels, même en cas de défaillances matérielles, logicielles ou réseau. Pour les entreprises, une perte d'accès, même de courte durée, peut entraîner des conséquences significatives : perte de revenus, perte de confiance des clients et des partenaires, voire des risques légaux dans certains secteurs.
¶ Haute Disponibilité (HA) et Systèmes de Gestion de Bases de Données (SGBD)
Les bases de données sont au cœur des systèmes d'information. Elles stockent et gèrent les données essentielles de nombreuses applications, ce qui les rend critiques pour la continuité des services. La spécificité des SGBD en matière de haute disponibilité réside dans leur nature transactionnelle et leur besoin de cohérence des données. En cas de panne ou d'interruption, il est impératif que les données restent cohérentes et que la continuité des transactions soit garantie.
¶ Les défis de la HA pour les SGBD
- Synchronisation et Cohérence : Les bases de données doivent rester cohérentes sur plusieurs nœuds en cas de réplication, pour éviter des divergences entre les copies de données.
- Gestion des Transactions : Les SGBD doivent s'assurer que toutes les transactions sont enregistrées correctement, même en cas de panne. Cela inclut la garantie que toutes les modifications de données sont soit entièrement appliquées, soit annulées (principe d'atomicité).
- Tolérance aux Pannes et Récupération : En cas de défaillance, le SGBD doit être capable de réorienter les requêtes vers un autre nœud et de se récupérer sans perte de données ni interruption significative.
- Équilibrage de Charge : Pour améliorer les performances tout en assurant la disponibilité, il est nécessaire de répartir la charge des requêtes sur plusieurs nœuds sans compromettre la cohérence.
¶ L'importance de la HA pour les SGBD dans un contexte moderne
Dans les environnements critiques, comme le commerce en ligne, la finance, la santé et les télécommunications, des bases de données disponibles 24/7 sont essentielles. De plus, avec l'augmentation du volume de données et des transactions, les entreprises ont besoin de solutions scalables qui maintiennent la performance sans sacrifier la disponibilité ni la cohérence.
Des solutions comme Galera Cluster pour MySQL/MariaDB et des technologies comme la réplication synchrone et les topologies multi-maîtres sont devenues des choix populaires pour répondre à ces besoins. Ces solutions permettent non seulement d'assurer la disponibilité des SGBD, mais aussi d'améliorer la résilience et la performance des systèmes de gestion de bases de données, essentielles dans un contexte où les interruptions ne sont pas acceptables.
¶ Présentation de Galera Cluster
![]()
Galera Cluster est une solution de réplication synchrone pour les bases de données MySQL et MariaDB. Il est conçu pour assurer une haute disponibilité et une tolérance aux pannes en permettant la répartition de la charge sur plusieurs nœuds. Voici ses principales fonctionnalités et avantages :
¶ Fonctionnalités de Galera Cluster
- Réplication Synchrone : Les transactions sont appliquées simultanément sur tous les nœuds du cluster, garantissant que chaque nœud est à jour. Cela permet une grande cohérence des données.
- Topologie Multi-Maîtres : Chaque nœud peut servir de maître, permettant des écritures sur n'importe quel nœud et une répartition de la charge plus efficace.
- Auto-récupération des Nœuds : Les nœuds qui rejoignent le cluster ou se reconnectent après une défaillance peuvent automatiquement se synchroniser avec les autres nœuds.
- Équilibrage de Charge : Avec des solutions comme HAProxy, on peut répartir les requêtes sur plusieurs nœuds, optimisant ainsi les performances du cluster.
¶ Avantages de Galera Cluster
- Tolérance aux Pannes : En cas de défaillance d'un nœud, le cluster peut continuer à fonctionner sans interruption.
- Cohérence des Données : La réplication synchrone assure que chaque nœud possède les mêmes données, réduisant les risques de divergences.
- Scalabilité : La configuration multi-maîtres permet d'ajouter des nœuds pour augmenter la capacité de traitement, à la fois en lecture et en écriture.
- Maintenance Simplifiée : Grâce à la synchronisation automatique des nœuds, la maintenance et la récupération après sinistre sont simplifiées.
Galera Cluster est une solution robuste et adaptée aux applications critiques qui nécessitent des performances élevées et une haute disponibilité pour leurs bases de données.
¶ Concepts clés à connaître
Quelques notions reviendront tout au long du TP, autant les poser dès maintenant :
- wsrep (Write-Set Replication) : le protocole de réplication utilisé par Galera. Toute écriture est encapsulée dans un writeset envoyé à tous les nœuds avant validation.
- Certification : mécanisme par lequel chaque nœud vérifie qu'un writeset peut être appliqué sans conflit. Si un conflit est détecté, la transaction est rejetée (certification failure).
- SST (State Snapshot Transfer) : copie complète des données d'un nœud sain vers un nouveau nœud (ou un nœud très en retard). Méthodes possibles :
rsync(bloquant),mariabackup(non-bloquant, recommandé),mysqldump. - IST (Incremental State Transfer) : copie incrémentale des writesets manqués par un nœud qui rejoint le cluster après une courte absence. Beaucoup plus rapide qu'un SST.
- Primary Component : la partition du cluster qui détient le quorum et qui accepte les écritures. Les nœuds isolés du Primary Component passent en mode
non-Primaryet refusent toute écriture (comportement de sécurité).
¶ Quorum
Dans un cluster qui utilise un quorum pour la haute disponibilité, il est recommandé d'avoir un nombre impair de nœuds. Le quorum est un mécanisme utilisé pour déterminer la majorité des nœuds actifs dans un cluster. Dans un cluster Galera, par exemple, un quorum auto basculant permet de décider si le cluster doit rester opérationnel ou basculer en mode dégradé en cas de défaillance de certains nœuds.
¶ Pourquoi un nombre impair de nœuds ?
Avoir un nombre impair de nœuds permet d'éviter les égalités lors du calcul du quorum, simplifiant ainsi la prise de décision pour maintenir la cohérence et l'intégrité des données dans le cluster. Si le nombre de nœuds est impair, le cluster peut obtenir une majorité plus facilement, ce qui évite les conflits. Dans un cluster avec un nombre pair de nœuds, il peut y avoir des situations de "split-brain", où deux partitions peuvent prétendre avoir la majorité, ce qui complique la gestion.
¶ Solutions pour un nombre pair de nœuds
Si vous avez un nombre pair de nœuds pour des raisons pratiques ou de charge de travail, une solution consiste à ajouter un nœud arbitre. Ce nœud arbitre participe au vote pour le quorum mais n'héberge pas de données. Cela permet d'obtenir une majorité plus simplement et d'éviter les conflits de quorum. Le package galera-arbitrator peut jouer ce rôle dans le cadre de Galera Cluster (nous le mettrons en pratique en fin de TP).
Le site officiel de Galera Cluster : https://galeracluster.com/
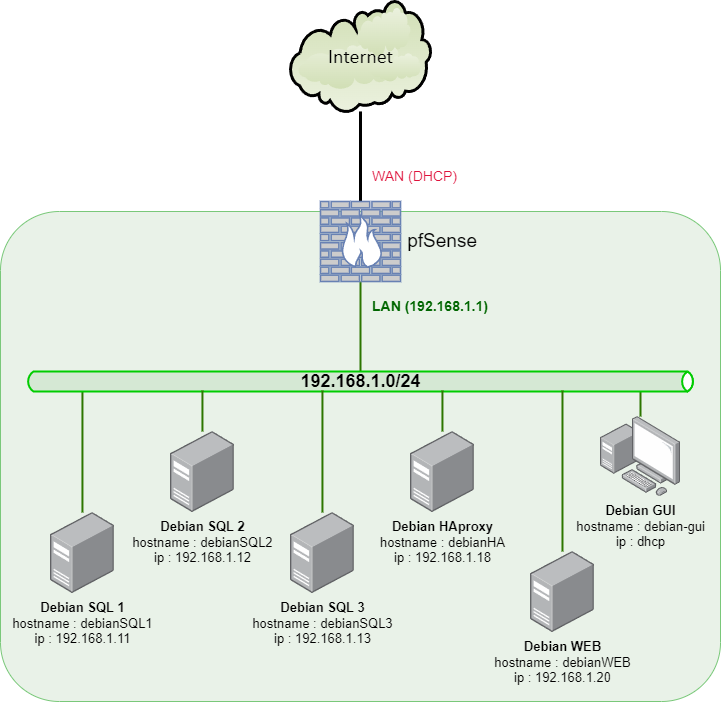
¶ Mise en pratique
¶ Prérequis
- Nous partons du minilab virtuel :
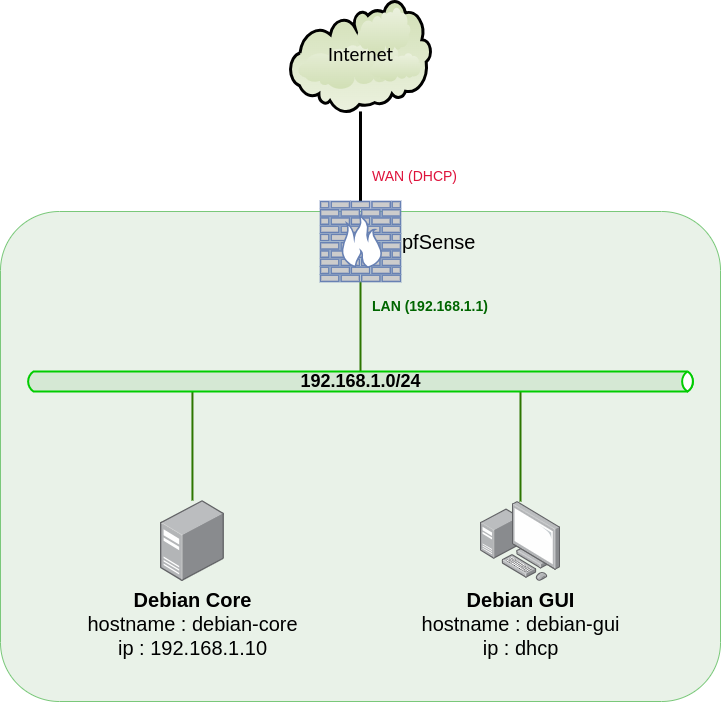
- Et nous ajoutons trois serveurs (par clonage lié de debian-core) :
- serveur 1 : hostname
debianSQL1, adresse IP192.168.1.11/24 - serveur 2 : hostname
debianSQL2, adresse IP192.168.1.12/24 - serveur 3 : hostname
debianSQL3, adresse IP192.168.1.13/24
- serveur 1 : hostname
Conservez une version du serveur debian core (par principe déjà), nous en aurons besoin plus loin pour HAProxy et Wordpress.
¶ Petit ménage ssh
Si vous clonez des VM sur lesquelles un serveur ssh est déjà installé, il est recommandé de réinitialiser les clés sur chaque serveur :
sudo rm /etc/ssh/ssh_host_*
sudo dpkg-reconfigure openssh-server
sudo systemctl restart ssh
Si vous étiez connecté en ssh au moment de cette opération, il faudra aussi vous déconnecter et réinitialiser la clé côté client (terminal sur GUI) :
ssh-keygen -R 192.168.1.X # adresse IP du serveur
NB : il faudra également y penser pour les prochaines VM dont nous aurons besoin.
Nous utiliserons debianGUI pour centraliser l'administration des serveurs (en SSH) et naviguer sur le WEB.
Le schéma avec les trois nœuds du cluster :
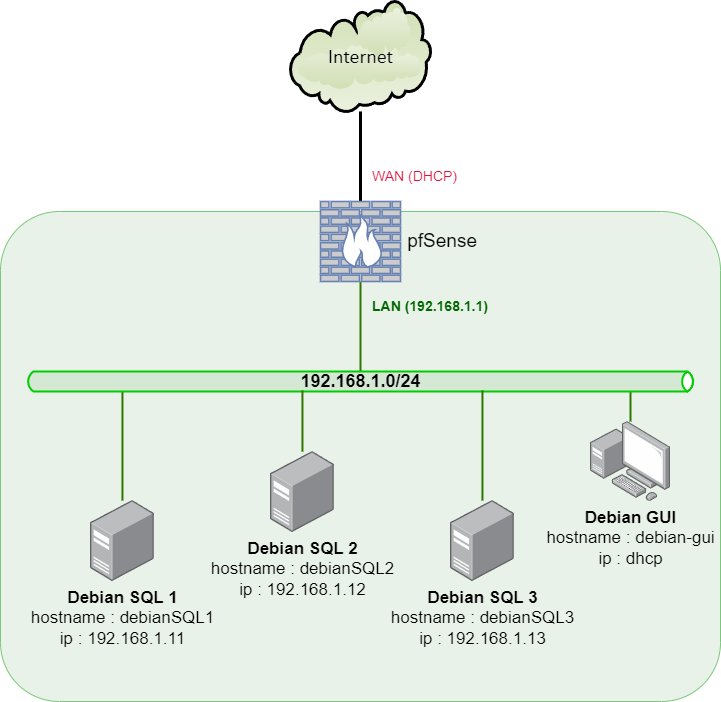
¶ Synchronisation du temps (sur les trois serveurs)
Galera n'est pas aussi strict que d'autres outils de HA (comme Pacemaker) sur la synchronisation horaire, mais des horloges désynchronisées rendent les logs illisibles et peuvent compliquer le diagnostic. On installe donc chrony sur les trois serveurs :
sudo apt update && sudo apt -y install chrony
sudo systemctl enable --now chrony
chronyc tracking
¶ Ports réseau utilisés par Galera
Pour mémoire (à ouvrir au pare-feu en production) :
| Port | Protocole | Usage |
|---|---|---|
| 3306 | TCP | MariaDB (clients SQL + SST avec mariabackup) |
| 4567 | TCP/UDP | Réplication Galera (traffic wsrep) |
| 4568 | TCP | IST (Incremental State Transfer) |
| 4444 | TCP | SST (State Snapshot Transfer) |
| 9200 | TCP | clustercheck (healthcheck HAProxy, ajouté plus loin) |
Dans notre minilab sans pare-feu actif, rien à faire ; mais on garde ça en tête pour la transposition en production.
¶ Installation d'un premier serveur MariaDB
Nous allons d'abord configurer un premier serveur de référence, sur lequel nous allons également installer une base de données et un utilisateur associé.
¶ Installation de MariaDB
Sur le serveur debianSQL1, installer le service MariaDB (ainsi que le nécessaire mariadb-backup). Ajoutons également curl, dont nous aurons besoin pour les tests :
sudo apt update && sudo apt upgrade && sudo apt -y install mariadb-server mariadb-backup curl
Normalement le package
galera-4est automatiquement installé avecmariadb-server, mais on ne risque rien à insister, avec la commande :sudo apt install galera-4
Procéder à l'habituelle configuration de base :
sudo mariadb-secure-installation
Dans notre contexte, les réponses à donner sont dans l'ordre : Entrée, n, n, y, y, y, y.
On édite le fichier de configuration de mariadb :
sudo nano /etc/mysql/mariadb.conf.d/50-server.cnf
Commenter la ligne bind-address pour autoriser des connexions en dehors de la machine hôte :
# bind-address = 127.0.0.1
Relancer le service :
sudo systemctl restart mariadb
¶ Vérification du moteur de stockage
Le moteur de stockage des bases de données doit être InnoDB ou XtraDB, MyISAM n'est pas pris en charge par Galera. InnoDB est en principe le moteur installé par défaut ; nous pouvons quand même vérifier.
La requête SQL ci-dessous va afficher quel est le moteur de stockage utilisé par défaut sur cette instance :
sudo mysql -u root -e "SHOW VARIABLES LIKE 'default_storage_engine';"
On obtient l'information en retour :
+------------------------+--------+
| Variable_name | Value |
+------------------------+--------+
| default_storage_engine | InnoDB |
+------------------------+--------+
1 row in set (0,001 sec)
¶ Création d'une base de données et son user
sudo mysql -u root
On arrive sur le shell mysql où nous allons créer la base de données pascaldb ainsi que l'utilisateur pascal (avec son mot de passe P@55word) qui aura (quasiment) tous les droits sur la base de données, depuis n'importe quel emplacement :
CREATE DATABASE pascaldb;
GRANT ALL ON pascaldb.* TO 'pascal'@'%' IDENTIFIED BY 'P@55word';
FLUSH PRIVILEGES;
exit;
¶ Configuration du cluster MariaDB
Nous allons maintenant, à partir de ce serveur initial, déployer le cluster sur les trois nœuds.
¶ Installation de MariaDB Galera Cluster
Sur les deux autres serveurs (debianSQL2 et debianSQL3), installez MariaDB, MariaDB-backup et curl :
sudo apt update && sudo apt upgrade && sudo apt -y install mariadb-server mariadb-backup curl
Procéder également à l'habituelle configuration de base :
sudo mariadb-secure-installation
¶ Configuration du serveur primaire
Sur le serveur primaire (debianSQL1), on renomme le fichier de configuration par défaut (backup préventif : bonne pratique) :
sudo mv /etc/mysql/mariadb.conf.d/60-galera.cnf /etc/mysql/mariadb.conf.d/60-galera.cnf.old
Puis on le modifie :
sudo nano /etc/mysql/mariadb.conf.d/60-galera.cnf
Insérer la configuration suivante :
[galera]
# Paramètres obligatoires
wsrep_on = ON
wsrep_provider = /usr/lib/galera/libgalera_smm.so
wsrep_cluster_name = "Galera_Cluster_PM"
wsrep_cluster_address = gcomm://192.168.1.11,192.168.1.12,192.168.1.13
# Identification du nœud (à adapter sur chaque serveur)
wsrep_node_address = "192.168.1.11"
wsrep_node_name = "debianSQL1"
# Méthode de SST : mariabackup est non-bloquant pour le donneur
wsrep_sst_method = mariabackup
# Format binlog et moteur InnoDB obligatoires pour Galera
binlog_format = row
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
innodb_force_primary_key = 1
# Accepter les connexions sur toutes les interfaces
bind-address = 0.0.0.0
# Log dédié Galera
log_error = /var/log/mysql/error-galera.log
Quelques explications :
wsrep_on = ON: activer la réplication en écriture via le provider wsrepwsrep_provider: emplacement de la librairie wsrepwsrep_cluster_name: le nom du cluster, doit être identique sur tous les nœudswsrep_cluster_address: adresses IP des différents nœuds du cluster (séparées par une virgule)wsrep_node_addressetwsrep_node_name: différents sur chaque nœud, facilitent énormément le diagnostic dans les logs et danswsrep_incoming_addresseswsrep_sst_method = mariabackup:mariabackupest non-bloquant pour le donneur (contrairement àrsync), c'est le choix recommandé en productionbinlog_format = row: indispensable pour Galera (format basé ligne, pas instruction)default_storage_engine = InnoDB: moteur de stockage par défautinnodb_autoinc_lock_mode = 2: mode pour l'auto-incrémentation, obligatoire pour Galera (mode "interleaved")innodb_force_primary_key = 1: Galera exige que toutes les tables aient une clé primaire ; cette option fait échouer unCREATE TABLEsans PK et évite donc une mauvaise surprise plus tardbind-address = 0.0.0.0: accepter les connexions sur toutes les interfaceslog_error: emplacement du fichier de log des erreurs (qui contient aussi des logs d'informations Galera)
¶ Démarrage du cluster
On va démarrer le cluster avec cet unique nœud primaire. Toujours sur le serveur 1 debianSQL1, arrêter le service MariaDB :
sudo systemctl stop mariadb
et initialiser le cluster :
sudo galera_new_cluster
À comprendre :
galera_new_clusterest un wrapper qui démarre MariaDB en passant temporairement--wsrep-new-cluster, ce qui équivaut àwsrep_cluster_address=gcomm://(adresse vide). C'est ce qui dit à Galera : "tu es le premier, crée le cluster". Cette commande ne s'utilise qu'une seule fois, au tout premier démarrage. Pour tous les démarrages suivants (y compris après reboot), on utilise simplementsudo systemctl start mariadb.
Ensuite, on va se connecter au shell MariaDB :
sudo mysql -u root
pour regarder combien de nœuds constituent notre cluster :
SHOW STATUS LIKE 'wsrep_cluster_size';
Normalement, un seul :
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 1 |
+--------------------+-------+
1 row in set (0,001 sec)
Toujours sous le shell SQL, la commande ci-dessous permet d'obtenir les informations sur l'état du cluster :
SHOW GLOBAL STATUS LIKE 'wsrep%';
Ce qui peut donner pour nous (je n'affiche qu'une partie de la sortie) :
+-------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------+
| Variable_name | Value |
+-------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------+
| wsrep_local_state_uuid | eb71b051-a048-11ef-8fe7-8f72caf18dad |
| wsrep_protocol_version | 11 |
| wsrep_last_committed | 1 |
...
| wsrep_local_state_comment | Synced |
...
| wsrep_incoming_addresses | 192.168.1.11:0 |
| wsrep_cluster_weight | 1 |
...
| wsrep_evs_state | OPERATIONAL |
...
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
...
+-------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------+
69 rows in set (0,002 sec)
Variables wsrep à retenir :
| Variable | Définition |
|---|---|
wsrep_cluster_size |
Nombre de nœuds vus dans le cluster |
wsrep_cluster_status |
Primary (cluster fonctionnel) ou non-Primary (quorum perdu, écritures refusées) |
wsrep_local_state_comment |
Synced (OK), Donor/Desynced (en train de donner un SST), Joiner (en train de recevoir), Joined (synchronisé mais pas encore Synced) |
wsrep_local_recv_queue_avg |
doit être proche de 0 ; si élevé, le nœud n'arrive pas à suivre la cadence |
wsrep_flow_control_paused |
si > 0, indique que le cluster ralentit volontairement pour permettre à un nœud lent de rattraper |
¶ Configuration des autres serveurs
Sur chacun des deux autres serveurs du cluster (debianSQL2 puis debianSQL3), on configure quasi à l'identique — en pensant bien à adapter wsrep_node_address et wsrep_node_name.
On backup le fichier de configuration par défaut :
sudo mv /etc/mysql/mariadb.conf.d/60-galera.cnf /etc/mysql/mariadb.conf.d/60-galera.cnf.old
Puis on édite le fichier :
sudo nano /etc/mysql/mariadb.conf.d/60-galera.cnf
Sur debianSQL2 :
[galera]
wsrep_on = ON
wsrep_provider = /usr/lib/galera/libgalera_smm.so
wsrep_cluster_name = "Galera_Cluster_PM"
wsrep_cluster_address = gcomm://192.168.1.11,192.168.1.12,192.168.1.13
wsrep_node_address = "192.168.1.12"
wsrep_node_name = "debianSQL2"
wsrep_sst_method = mariabackup
binlog_format = row
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
innodb_force_primary_key = 1
bind-address = 0.0.0.0
log_error = /var/log/mysql/error-galera.log
Sur
debianSQL3: idem mais avecwsrep_node_address = "192.168.1.13"etwsrep_node_name = "debianSQL3".
Enfin, sur les deux nœuds, on redémarre simplement MariaDB :
sudo systemctl restart mariadb
Les bases de données existantes des nœuds
debianSQL2etdebianSQL3seront supprimées par le SST initial. Il n'y a que les bases de données du premier nœud qui vont exister suite à l'intégration au cluster.
¶ Vérification du cluster
Sur chacun des serveurs, on peut vérifier l'état local du provider. Connectez-vous à MariaDB :
sudo mysql -u root
et vérifiez l'état du cluster :
SHOW STATUS LIKE 'wsrep_%';
Points à vérifier :
wsrep_cluster_size=3wsrep_cluster_status=Primarywsrep_local_state_comment=Syncedwsrep_local_recv_queue_avg≈0
Si un nœud n'est pas dans cet état suite à une perte de connexion, il suffit en général de relancer le service mariadb dessus (sudo systemctl restart mariadb).
MariaDB [(none)]> show global status like 'wsrep%';
+-------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------+
| Variable_name | Value |
+-------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------+
| wsrep_local_state_uuid | 2be432cb-bfb4-11f0-a161-7a324ee3ab63 |
...
| wsrep_local_recv_queue_avg | 0.1 |
...
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
...
| wsrep_cluster_size | 3 |
| wsrep_cluster_state_uuid | 2be432cb-bfb4-11f0-a161-7a324ee3ab63 |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
...
+-------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------+
72 rows in set (0,001 sec)
¶ Healthcheck "intelligent" pour HAProxy
Avant d'aller plus loin, mettons en place un vrai healthcheck Galera. On pourrait utiliser un simple check tcp/3306 pour HAproxy, mais alors un nœud pourrait être détecté up alors qu'il ne serait pas parfaitement opérationnel, comme :
- en train de recevoir un SST (
Donor/Desynced) → ne doit pas servir de trafic - isolé du cluster (
non-Primary) → refuse les écritures - en cours de rejoint (
Joinedmais pas encoreSynced) → données potentiellement obsolètes
D'autre part, cette solution va surtout nous permettre d'expérimenter la conception d'un service de healthcheck "customisé". En effet, ce besoin est essentiel dans les architectures HA, y compris dans des clusters de conteneurs orchestrés (Kubernetes, par exemple).
La solution standard est le script clustercheck pour MariaDB, qu'on va exposer via avec systemd (systemd.socket + systemd.service). HAProxy interrogera ce port, et clustercheck répondra HTTP 200 uniquement si le nœud est réellement utilisable.
Certains tutoriels proposeront
xinetdpour réaliser ce service exposé. C'était l'approche historique standard, mais elle ne fonctionne plus de manière fiable sur Debian récente. On utilisera donc systemd socket activation — c'est la méthode désormais recommandée par le mainteneur officiel de clustercheck, et accessoirement la preuve quesystemd- malgré ses détracteurs- propose ici une solution plus simple et plus moderne.
¶ Création du user MySQL dédié au healthcheck
A faire une seule fois depuis n'importe quel nœud du cluster, puisque Galera répliquera l'opération.
sudo mysql -u root
CREATE USER 'clustercheckuser'@'localhost' IDENTIFIED BY 'clustercheckpassword!';
GRANT PROCESS ON *.* TO 'clustercheckuser'@'localhost';
FLUSH PRIVILEGES;
exit;
¶ À faire sur les trois nœuds Galera
¶ Installation du script
Le script clustercheck n'est plus livré avec les versions récentes de mariadb, mais il est toujours maintenu par des contributeurs actifs, comme https://github.com/gitmstoute/mariadb-clustercheck/
On crée le script clustercheck :
sudo nano /usr/local/bin/clustercheck
Insérer le contenu à récupérer sur le dépôt indiqué ci-dessus. Voici une version simplifiée :
#!/bin/bash
# if the disabled file is present, return 503. This allows
# admins to manually remove a node from a cluster easily.
if [ -e "/var/tmp/clustercheck.disabled" ]; then
echo -en "HTTP/1.1 503 Service Unavailable\r\n"
echo -en "Content-Type: text/plain\r\n"
echo -en "Connection: close\r\n"
echo -en "Content-Length: 51\r\n"
echo -en "\r\n"
echo -en "Mariadb node is manually disabled.\r\n"
sleep 0.1
exit 1
fi
MYSQL_USERNAME="clustercheckuser"
MYSQL_PASSWORD="clustercheckpassword!"
TIMEOUT=10
MYSQL_CMDLINE="mysql -nNE --connect-timeout=$TIMEOUT --user=${MYSQL_USERNAME} --password=${MYSQL_PASSWORD}"
# Perform the query to check the wsrep_local_state
#
WSREP_STATUS=$($MYSQL_CMDLINE -e "SHOW STATUS LIKE 'wsrep_local_state';" 2>/dev/null | tail -1)
if [[ "${WSREP_STATUS}" == "4" ]]
then
# Galera node local state is 'Synced' => return HTTP 200
echo -en "HTTP/1.1 200 OK\r\n"
echo -en "Content-Type: text/plain\r\n"
echo -en "Connection: close\r\n"
echo -en "Content-Length: 40\r\n"
echo -en "\r\n"
echo -en "Mariadb node is synced.\r\n"
sleep 0.1
exit 0
else
# Galera node local state is not 'Synced' => return HTTP 503
echo -en "HTTP/1.1 503 Service Unavailable\r\n"
echo -en "Content-Type: text/plain\r\n"
echo -en "Connection: close\r\n"
echo -en "Content-Length: 44\r\n"
echo -en "\r\n"
echo -en "Mariadb node is not synced.\r\n"
sleep 0.1
exit 1
fi
Attention, les user et mots de passe par défaut (lignes 17 & 18) sont ceux définis lors de la création du user mySQL à l'étape précédente. Ils doivent correspondre.
Rendre le script exécutable :
sudo chmod +x /usr/local/bin/clustercheck
Vérifier :
which clustercheck
# attendu : /usr/local/bin/clustercheck
¶ Créer le socket systemd
sudo nano /etc/systemd/system/mysqlchk.socket
Contenu :
[Unit]
Description=Galera Cluster Health Check Socket
[Socket]
ListenStream=9200
Accept=yes
[Install]
WantedBy=sockets.target
Accept=yesindique à systemd de créer une nouvelle instance du service à chaque connexion entrante (comportement "à la xinetd").
¶ Créer le template de service
sudo nano /etc/systemd/system/mysqlchk@.service
Contenu :
[Unit]
Description=Galera Cluster Health Check Service
[Service]
User=mysql
Group=mysql
ExecStart=-/usr/local/bin/clustercheck
StandardInput=socket
StandardOutput=socket
StandardError=journal
Quelques explications :
- Le
@dans le nom de fichier indique un template :systemdl'instancie à la volée. User=mysql: on lance sous l'identité du user MariaDB (accès garanti au socket MariaDB local).ExecStart=-/usr/local/bin/clustercheck: le-devant le chemin dit "ignorer les codes de retour non nuls" (puisque clustercheck retourne 1 légitimement en cas de 503).StandardInput=socketetStandardOutput=socket:systemdbranche la socket TCP entrante sur stdin/stdout du script.
¶ Activer et démarrer le socket
sudo systemctl daemon-reload
sudo systemctl enable --now mysqlchk.socket
sudo systemctl status mysqlchk.socket
On doit obtenir :
● mysqlchk.socket - Galera Cluster Health Check Socket
Loaded: loaded ...
Active: active (listening) since ...
Invocation: 6d450d...
Listen: [::]:9200 (Stream)
Accepted: 0; Connected: 0;
Tasks: 0 (limit: 2301)
Memory: 8K (peak: 256K)
CPU: 439us
CGroup: /system.slice/mysqlchk.socket
¶ Test du healthcheck
Sur le nœud local :
curl -i http://127.0.0.1:9200
Réponse attendue si le nœud est sain :
HTTP/1.1 200 OK
Content-Type: text/plain
Connection: close
Content-Length: 40
Mariadb node is synced.
curl: (56) Recv failure: Connexion ré-initialisée par le correspondant
La dernière ligne signifie que le flux TCP a été terminé un peu brutalement (RST et non FIN) par le socket. C'est sans incidence, seule la première ligne importe.
Si le nœud est désynchronisé :
HTTP/1.1 503 Service Unavailable
Content-Type: text/plain
Connection: close
Content-Length: 44
Mariadb node is not synced.
🔔 Rappel : il faut réaliser cette installation sur chacun des noeuds.
Ensuite, on peut tester les différents HealthCheck (depuis n'importe quelle machine du réseau, comme la GUI par exemple) :
curl -i http://192.168.1.11:9200
curl -i http://192.168.1.12:9200
curl -i http://192.168.1.13:9200
¶ Mise en situation avec WordPress et HAProxy
Le cluster est désormais opérationnel. Si un serveur primaire tombe en panne, les autres serveurs continueront à fonctionner normalement. Lorsque le serveur primaire sera de nouveau opérationnel, il se synchronisera automatiquement avec les autres.
Pour la gestion du failover et la répartition de charge, nous ajoutons HAProxy devant nos serveurs MariaDB.
¶ Ajout d'un HAProxy
On ajoute à notre réseau un nouveau serveur Debian Core :
- serveur 4 : hostname
debianHA, adresse IP192.168.1.18/24
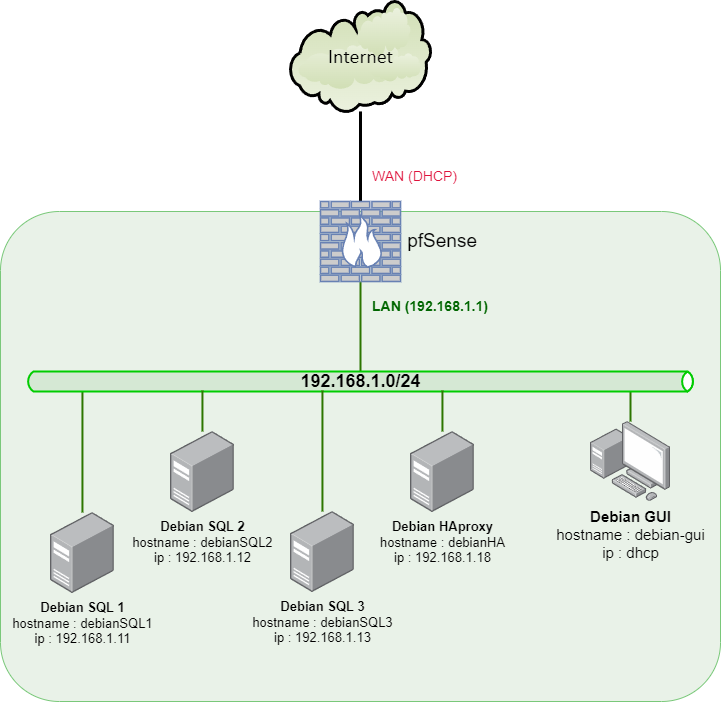
On y installe le service HAProxy :
sudo apt update && sudo apt upgrade && sudo apt -y install haproxy
¶ Configuration HAProxy : deux stratégies possibles
Avant de configurer, un point conceptuel important : comment répartir les écritures dans un cluster Galera ?
¶ Stratégie A — Round-robin (toutes les écritures sur tous les nœuds)
C'est ce qui semble naturel : on profite du multi-master. Mais Galera doit certifier chaque transaction, et deux écritures concurrentes sur deux nœuds différents touchant la même ligne provoquent une certification failure au commit (une des deux est rollback, le client doit retry).
Pour un usage de test ou une charge faible, c'est sans conséquence visible. Pour une charge réelle multi-utilisateurs (ex. cluster web avec beaucoup d'inserts/updates concurrents), ça génère des erreurs.
¶ Stratégie B — Single-writer (un seul nœud actif, les autres en backup)
Toutes les écritures vont sur un seul nœud (debianSQL1 par exemple). Les deux autres sont en backup HAProxy : ils ne reçoivent du trafic que si le writer tombe. On garde donc les bénéfices du failover automatique, sans le risque de certification failure.
C'est la configuration recommandée en production, bien qu'elle soit a priori contre-intuitive.
¶ Configuration HAProxy
Éditez une nouvelle version du fichier de configuration :
sudo mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
sudo nano /etc/haproxy/haproxy.cfg
Remplacez par cette configuration (incluant les deux stratégies, sur deux ports différents — vous activerez l'une ou l'autre selon le test à mener) :
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode tcp
option tcplog
timeout connect 10s
timeout client 1m
timeout server 1m
# Page de stats
listen stats
bind *:8404
mode http
stats enable
stats uri /stats
stats realm HAProxy\ Statistics
stats auth admin:password
stats refresh 5s
# ─── Stratégie A : Round-robin (port 3306) ───────────────────────────
frontend mysql_front_rr
bind *:3306
mode tcp
default_backend galera_cluster_rr
backend galera_cluster_rr
mode tcp
balance roundrobin
option httpchk GET /
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server galera1 192.168.1.11:3306 check port 9200 weight 1
server galera2 192.168.1.12:3306 check port 9200 weight 1
server galera3 192.168.1.13:3306 check port 9200 weight 1
# ─── Stratégie B : Single-writer avec failover (port 3307) ───────────
frontend mysql_front_sw
bind *:3307
mode tcp
default_backend galera_cluster_sw
backend galera_cluster_sw
mode tcp
balance first
option httpchk GET /
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server galera1 192.168.1.11:3306 check port 9200
server galera2 192.168.1.12:3306 check port 9200 backup
server galera3 192.168.1.13:3306 check port 9200 backup
¶ Explications des options importantes
mode tcp: HAProxy gère les connexions en mode TCP, adapté pour MySQL/MariaDB.option httpchk GET /+check port 9200: le vrai healthcheck Galera. HAProxy fait une requête HTTPGET /sur le port 9200 (notreclustercheck). Si la réponse n'est pas un200 OK, le nœud est marqué DOWN.default-server inter 3s fall 3 rise 2:inter 3s: vérification toutes les 3 secondesfall 3: 3 vérifications en échec → nœud marqué DOWNrise 2: 2 vérifications réussies → nœud remarqué UP
on-marked-down shutdown-sessions: quand un nœud passe DOWN, les sessions actives dessus sont fermées (évite de garder des connexions zombies).balance roundrobin(stratégie A) : répartition équitable des nouvelles connexions.balance first+backup(stratégie B) : toutes les connexions vont sur le premier serveur "UP" déclaré ; lesbackupne servent qu'en cas de panne.
¶ Redémarrer HAProxy
sudo systemctl restart haproxy
¶ Vérifier l'état des connexions et des nœuds
Ouvrez un navigateur sur http://192.168.1.18:8404/stats (identifiants admin / password).
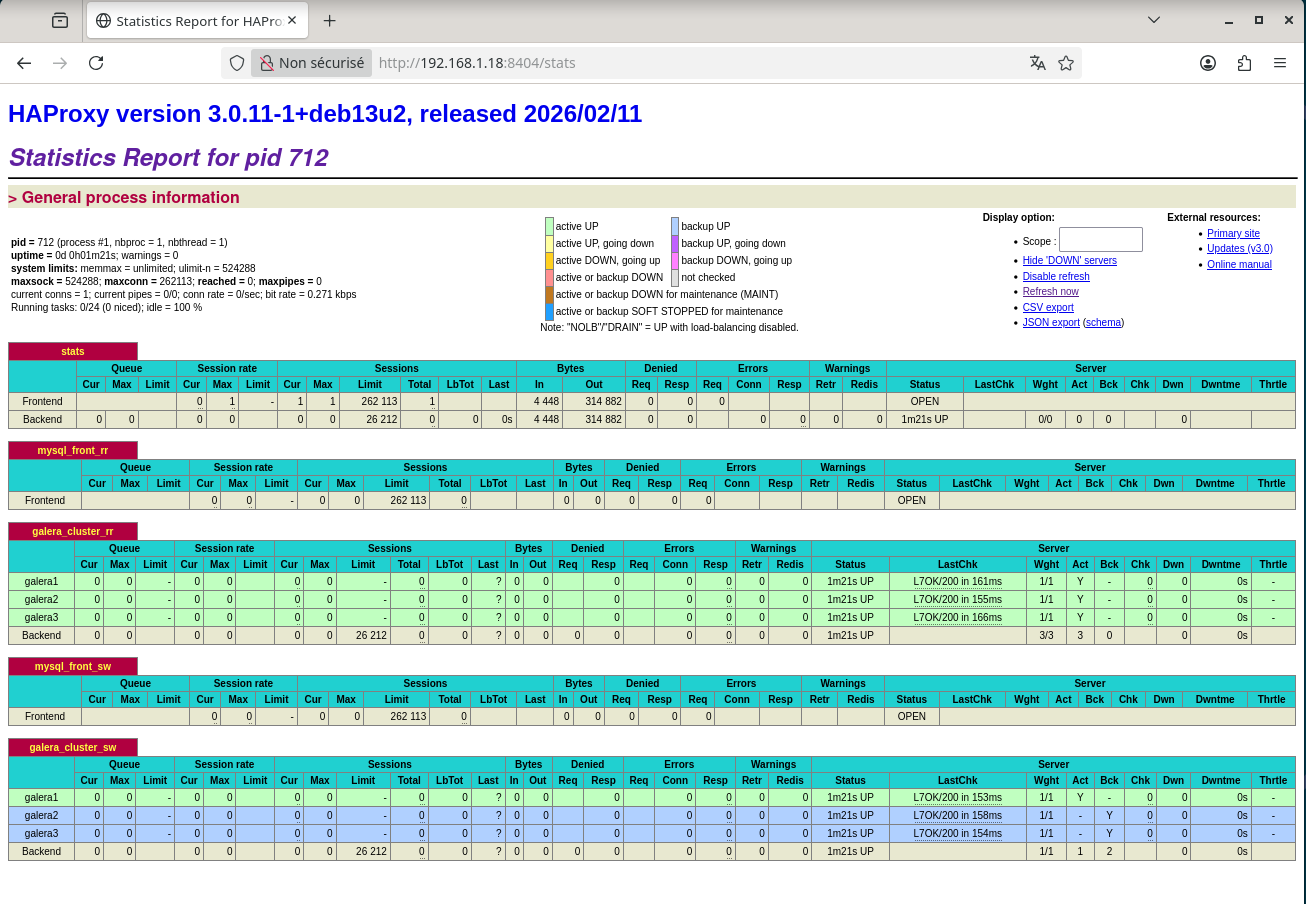
On y voit les deux backends (galera_cluster_rr et galera_cluster_sw) avec :
- pour le round-robin : 3 serveurs UP (verts)
- pour le single-writer : galera1 UP en mode actif, galera2/galera3 UP en mode "backup"
¶ Ajout d'un serveur WordPress
On ajoute à notre réseau un nouveau serveur Debian Core :
- serveur 5 : hostname
debianWEB, adresse IP192.168.1.20/24
On installe le service nginx (serveur http) ainsi que l'utilitaire wget :
sudo apt update && sudo apt upgrade && sudo apt -y install nginx wget
On installe également le service php-fpm (moteur de script php) :
sudo apt install php-fpm
On repère la version de PHP :
php -v
Ici on aura 8.4 :
PHP 8.4.21 (cli) (built: May 8 2026 05:56:48) (NTS)
Copyright (c) The PHP Group
Built by Debian
Zend Engine v4.4.21, Copyright (c) Zend Technologies
with Zend OPcache v8.4.21, Copyright (c), by Zend Technologies
On modifie le fichier de configuration par défaut de nginx :
sudo mv /etc/nginx/sites-available/default /etc/nginx/sites-available/default.bak
sudo nano /etc/nginx/sites-available/default
Remplacez par cette configuration simple (adapter au besoin la ligne fastcgi_pass selon la version de PHP, ligne 11) :
server {
listen 80 default_server;
root /var/www/html/wordpress;
index index.php index.html index.htm;
server_name _;
location / {
try_files $uri $uri/ =404;
}
location ~ \.php$ {
include snippets/fastcgi-php.conf;
fastcgi_pass unix:/run/php/php8.4-fpm.sock;
}
location ~ /\.ht {
deny all;
}
}
On redémarre le service :
sudo systemctl restart nginx
On récupère le package WordPress dans le document root :
cd /var/www/html
sudo wget https://wordpress.org/latest.tar.gz
On l'extrait :
sudo tar -xvzf latest.tar.gz
On change le propriétaire du répertoire et de tout son contenu à www-data (user affecté au serveru nginx) :
sudo chown -R www-data:www-data wordpress
On installe l'extension php pour mysql :
sudo apt -y install php-mysql
Puis on finalise l'installation de WordPress sur http://192.168.1.20 :
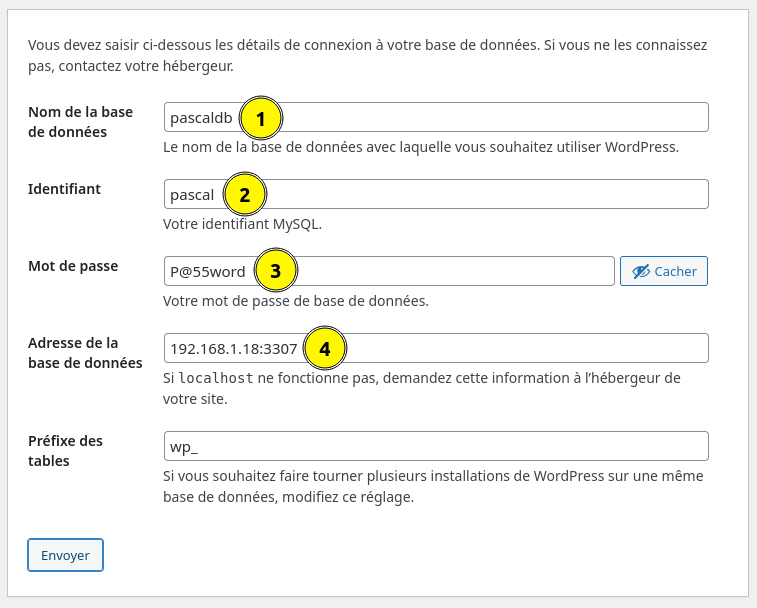
- Le nom de la base de données (définie au tout début du TP)
- L'utilisateur avec les droits sur la base (idem)
- Le mot de passe associé (idem)
- La base de données n'est pas sur le serveur lui-même (
localhost) mais bien sur le cluster MariaDB qu'on vient tout juste de configurer, accessible via HAProxy sur192.168.1.18. On spécifie le port selon la stratégie testée :3306(round-robin) ou3307(single-writer)
¶ Tests de basculement (différents scénarios)
À ce stade, tout en gardant un œil sur :
- la page de monitoring HAProxy (
http://192.168.1.18:8404/statsdepuis la GUI) - le site WordPress (toujours sur GUI)
- les variables
wsrep_*importantes et les journaux sur chaque nœud, via le terminal, en utilisant un script que l'IA va nous générer rapidement.
¶ Script de surveillance (sur chaque noeud du cluster)
On ajoute l'utilisateur au groupe systemd-journal :
sudo adduser $USER systemd-journal
(il faudra se déconnecter puis se reconnecter pour avoir le droit effectif)
On crée un script spécifique :
sudo nano /usr/local/bin/galera-status
Avec ce contenu (merci ClaudeAI !) :
#!/bin/bash
#
# galera-status — vue synthétique de l'état d'un nœud Galera
# Usage : galera-status (one-shot)
# watch -n 2 -c galera-status (mode temps réel)
#
# Couleurs activées par défaut (respecte la convention NO_COLOR)
if [[ -n "$NO_COLOR" || "$TERM" == "dumb" ]]; then
BOLD=""; DIM=""; RESET=""; RED=""; GREEN=""; YELLOW=""; CYAN=""
else
BOLD=$'\e[1m'; DIM=$'\e[2m'; RESET=$'\e[0m'
RED=$'\e[31m'; GREEN=$'\e[32m'; YELLOW=$'\e[33m'; CYAN=$'\e[36m'
fi
HOST=$(hostname)
NOW=$(date '+%Y-%m-%d %H:%M:%S')
HEAVY="═══════════════════════════════════════════════════════════════"
LIGHT="───────────────────────────────────────────────────────────────"
color_status() {
case "$1" in
Primary|Synced|ON|OPERATIONAL) echo "${GREEN}$1${RESET}" ;;
non-Primary|OFF|Disconnected) echo "${RED}$1${RESET}" ;;
Donor*|Joiner|Joined) echo "${YELLOW}$1${RESET}" ;;
*) echo "$1" ;;
esac
}
kv() {
printf " %-22s : %s\n" "$1" "$(color_status "$2")"
}
# Récupération des données via clustercheckuser (pas de sudo nécessaire)
STATUS=$(mariadb -u clustercheckuser -p'clustercheckpassword!' -BN -e "
SHOW STATUS WHERE Variable_name IN (
'wsrep_cluster_size',
'wsrep_cluster_status',
'wsrep_local_state_comment',
'wsrep_connected',
'wsrep_ready',
'wsrep_local_recv_queue_avg',
'wsrep_flow_control_paused',
'wsrep_incoming_addresses',
'wsrep_evs_state'
);
" 2>/dev/null)
if [[ -z "$STATUS" ]]; then
echo "${BOLD}${RED}${HEAVY}${RESET}"
printf " ${BOLD}%-22s${RESET} %s\n" "$HOST" "$NOW"
echo "${BOLD}${RED}${HEAVY}${RESET}"
echo
echo " ${BOLD}${RED}⚠ MariaDB INJOIGNABLE${RESET}"
echo
echo " ${BOLD}Dernières entrées du journal :${RESET}"
journalctl -u mariadb -n 10 --no-pager -o cat 2>/dev/null | sed 's/^/ /'
exit 1
fi
get() { echo "$STATUS" | awk -v k="$1" '$1==k {for(i=2;i<=NF;i++) printf "%s%s", $i, (i==NF?"":" ")}'; }
CLUSTER_SIZE=$(get wsrep_cluster_size)
CLUSTER_STATUS=$(get wsrep_cluster_status)
LOCAL_STATE=$(get wsrep_local_state_comment)
CONNECTED=$(get wsrep_connected)
READY=$(get wsrep_ready)
RECV_QUEUE=$(get wsrep_local_recv_queue_avg)
FLOW_PAUSED=$(get wsrep_flow_control_paused)
INCOMING=$(get wsrep_incoming_addresses)
EVS_STATE=$(get wsrep_evs_state)
HC_CODE=$(curl -s -o /dev/null -w "%{http_code}" --max-time 1 http://127.0.0.1:9200 2>/dev/null)
case "$HC_CODE" in
200) HC_DISPLAY="${GREEN}200 OK${RESET}" ;;
503) HC_DISPLAY="${YELLOW}503 Service Unavailable${RESET}" ;;
000) HC_DISPLAY="${RED}injoignable${RESET}" ;;
"") HC_DISPLAY="${RED}injoignable${RESET}" ;;
*) HC_DISPLAY="${RED}${HC_CODE}${RESET}" ;;
esac
echo "${BOLD}${CYAN}${HEAVY}${RESET}"
printf " ${BOLD}%-22s${RESET} %s\n" "$HOST" "$NOW"
echo "${BOLD}${CYAN}${HEAVY}${RESET}"
echo
kv "Cluster size" "$CLUSTER_SIZE"
kv "Cluster status" "$CLUSTER_STATUS"
kv "Local state" "$LOCAL_STATE"
kv "Connected" "$CONNECTED"
kv "Ready" "$READY"
kv "EVS state" "$EVS_STATE"
kv "Recv queue avg" "$RECV_QUEUE"
kv "Flow control paused" "$FLOW_PAUSED"
printf " %-22s : %s\n" "Healthcheck (9200)" "$HC_DISPLAY"
echo
echo "${DIM}${LIGHT}${RESET}"
echo " ${BOLD}Membres du cluster :${RESET}"
echo "$INCOMING" | tr ',' '\n' | sed 's/:0$//' | while read -r member; do
[[ -n "$member" ]] && echo " • $member"
done
echo "${DIM}${LIGHT}${RESET}"
echo
echo " ${BOLD}Dernières entrées WSREP du journal :${RESET}"
journalctl -u mariadb -n 100 --no-pager -o cat 2>/dev/null \
| grep -i wsrep \
| tail -8 \
| sed 's/^/ /'
echo "${BOLD}${CYAN}${HEAVY}${RESET}"
On le rend exécutable :
sudo chmod +x /usr/local/bin/galera-status
Et on le lance via watch pour une actualisation permanente :
watch -n 2 -c galera-status
On va dérouler une série de scénarios qui couvrent les comportements typiques de Galera.
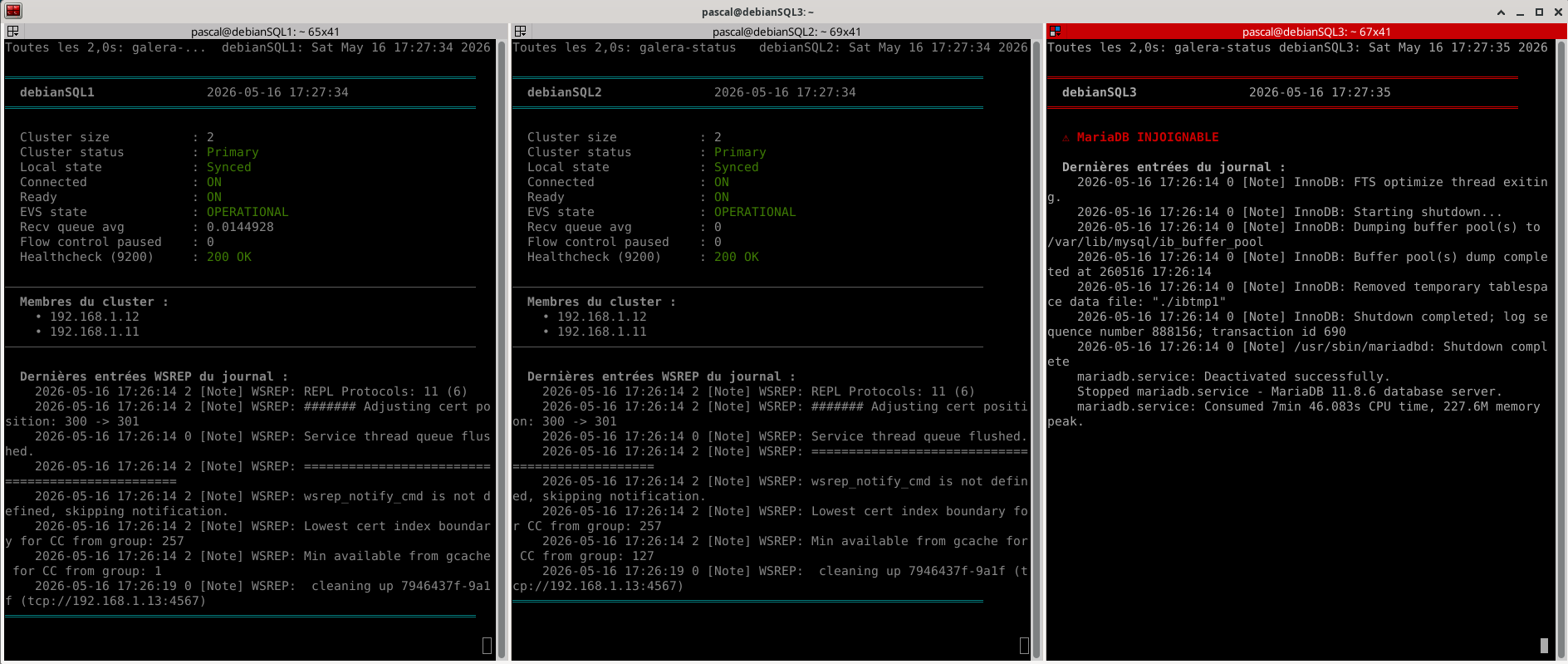
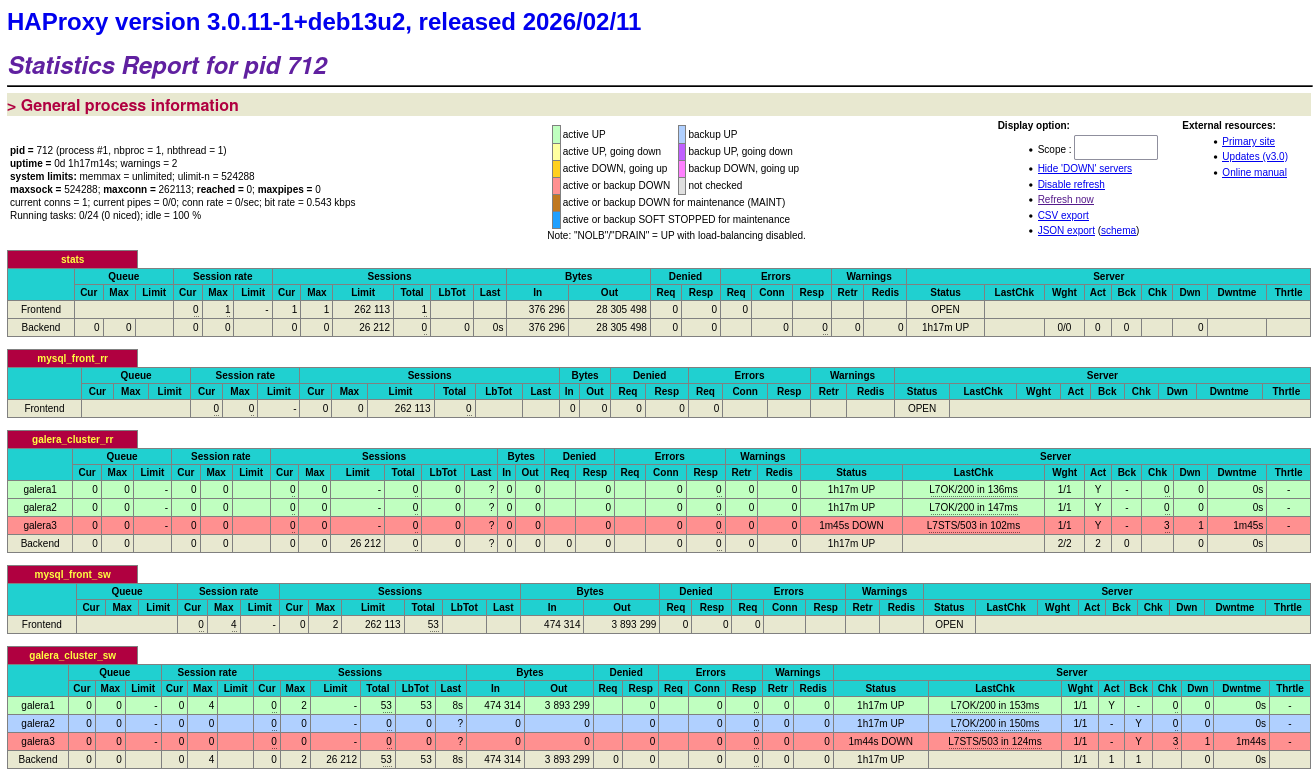
¶ Scénario 1 : arrêt propre d'un nœud non-writer
Sur debianSQL3 (depuis la console native de la VM, pour conserver la visu sur GUI) :
sudo systemctl stop mariadb
Observations attendues :
- Page HAProxy stats :
galera3passe en DOWN sous 3 à 9 secondes (seloninter/fall). - Sur
debianSQL1etdebianSQL2:wsrep_cluster_size=2,wsrep_cluster_status=Primary(le quorum tient à 2 sur 3). - WordPress continue à fonctionner normalement, aucune interruption.
Relancer debianSQL3 :
sudo systemctl start mariadb
Observations :
- Dans les logs, on voit le nœud effectuer un IST (Incremental State Transfer) — il rattrape juste les writesets manqués.
- Sous quelques secondes,
wsrep_cluster_size=3,wsrep_local_state_comment=Synced. - HAProxy le remet UP après
rise 2checks réussis.
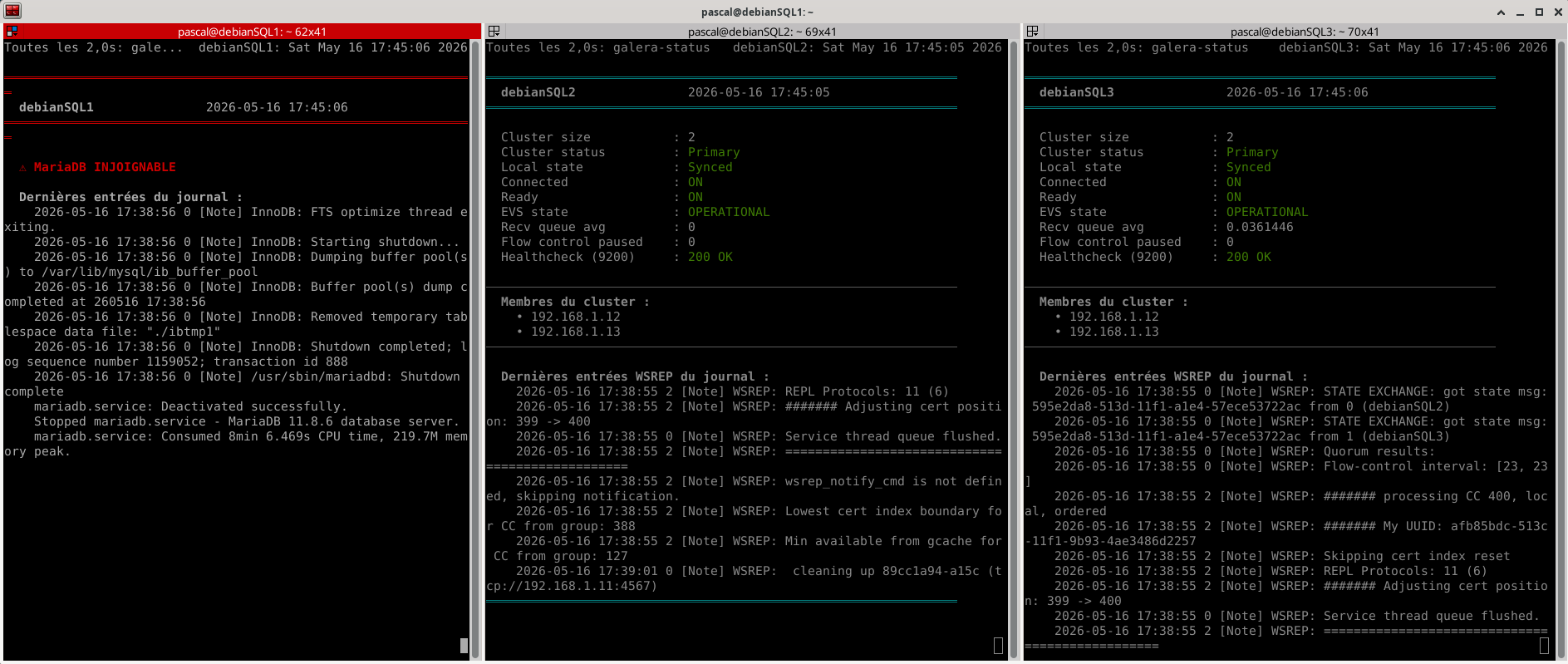
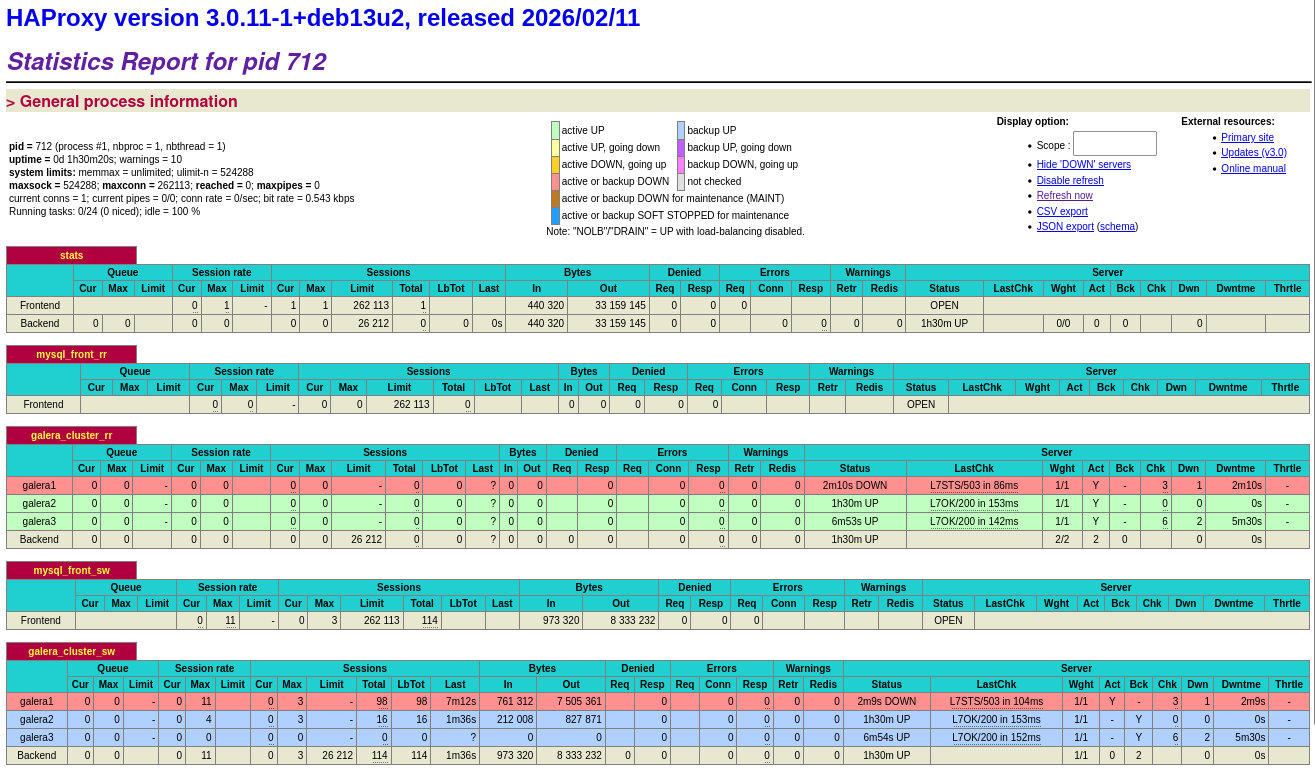
¶ Scénario 2 : panne du nœud writer (stratégie B)
Si vous n'avez pas choisi la stratégie B au moment de confgurer Wordpress, il est possible de changer en indiquant le port 3307 (single-writer) dans le fichier wp-config.php du serveur debianWEB :
define( 'DB_HOST', '192.168.1.18:3307' );
Sur debianSQL1 (le writer principal, toujours via la console native) :
sudo systemctl stop mariadb
Observations attendues :
- HAProxy détecte la panne en quelques secondes et bascule automatiquement sur
galera2(premier backup). - WordPress continue à fonctionner — éventuellement une erreur transitoire le temps de la bascule, puis tout reprend.
- Page stats :
galera1DOWN,galera2UP en mode actif.
Relancer debianSQL1 :
sudo systemctl start mariadb
Avec balance first, dès que galera1 repasse UP, HAProxy y renvoie le trafic (les sessions en cours sur galera2 restent jusqu'à fermeture, mais les nouvelles vont sur galera1). C'est le comportement de "préemption".
¶ Scénario 3 : perte de quorum
Vérifiez les comportements selon ces cas :
- Couper successivement
debianSQL2etdebianSQL3(laisser tournerdebianSQL1),- soir par un deconnexion au réseau :
sudo ip link set enp0s3 down - soit par un arrêt des services
sudo systemctl stop mariadb
- soir par un deconnexion au réseau :
- Rétablir
debianSQL2etdebianSQL3- reconnexion au réseau :
sudo ip link set enp0s3 up - relance des services
sudo systemctl start mariadb
- reconnexion au réseau :
- Faites la même chose mais en coupant les deux liens simultanément.
- le cluster va probablement être "cassé" et se mettre dans un état dégradé.
- voyez plus bas la procédure de récupération possible.
¶ Scénario 4 : rejoin avec SST volumineux
Couper debianSQL3 :
sudo systemctl stop mariadb
Pendant qu'il est arrêté, faire beaucoup d'écritures dans WordPress (créer 50 articles, importer du contenu, …). L'objectif est de générer suffisamment de writesets pour que l'IST ne suffise plus et qu'un SST complet soit déclenché au rejoint.
Relancer debianSQL3 :
sudo systemctl start mariadb
Observer les logs sur debianSQL3 et sur le nœud donneur.
Observations attendues :
- Sur
debianSQL3: passage par les étatsJoiner→Joined→Synced. - Sur le donneur (par ex.
debianSQL2) : passage enDonor/Desyncedpendant la durée du SST. Grâce àmariabackup, ce nœud continue à servir le trafic (contrairement àrsyncqui le bloquerait). - Dans la page HAProxy stats : le nœud donneur peut temporairement basculer en DOWN (selon
clustercheckqui considèreDonor/Desyncedcomme non-utilisable). C'est volontaire : on évite d'envoyer du trafic à un nœud occupé à donner un SST.
¶ Scénario 5 : crash total (arrêt brutal des trois nœuds)
Voici une situation qui ne doit pas arriver, l'intérêt du cluster est qu'il n'est jamais arrêté, avec la possibilité de maintenance possible sur un serveur à la fois, la disponibilité étant alors conservée sur les deux restants. Je vous recommande avant de lancer ce test d'éteindre les VM et de faire une snapshot de chacune.
Eteindre simultanément les trois VM, avec par exemple une extinction programmée à une heure identique sur les trois noeuds :
sudo shutdown 16:30
Rallumer les trois VM et observer :
sudo systemctl status mariadb
Résultat attendu :
● mariadb.service - MariaDB 11.8.6 database server
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; preset: enabled)
Active: activating (start) since Sat 2026-05-16 18:32:46 CEST; 3min 17s ago
Job: 97
Invocation: 5f6d9e8f72d74437a11c747e2acebb1a
Docs: man:mariadbd(8)
https://mariadb.com/kb/en/library/systemd/
Process: 676 ExecStartPre=/bin/sh -c [ ! -e /usr/bin/galera_recovery ] && VAR= || VAR=`/usr/bin/galera_recovery`; [ $? -eq 0 ] && ech>
Main PID: 801 (mariadbd)
Tasks: 7 (limit: 15190)
Memory: 202.8M (peak: 205M)
CPU: 1.715s
CGroup: /system.slice/mariadb.service
└─801 /usr/sbin/mariadbd --wsrep_start_position=89ced53c-507c-11f1-9a45-5b1bd314ade1:638
mai 16 18:32:57 debianSQL1 mariadbd[801]: own_index: 0
mai 16 18:32:57 debianSQL1 mariadbd[801]: members(3):
mai 16 18:32:57 debianSQL1 mariadbd[801]: 0: a381a02e-5141-11f1-8bf8-567c01eab0d6, debianSQL1
mai 16 18:32:57 debianSQL1 mariadbd[801]: 1: e0561abe-513f-11f1-aa18-233b1a0a800b, unspecified
mai 16 18:32:57 debianSQL1 mariadbd[801]: 2: e53a88db-513f-11f1-af51-870c8b5a9d77, unspecified
mai 16 18:32:57 debianSQL1 mariadbd[801]: =================================================
mai 16 18:32:57 debianSQL1 mariadbd[801]: 2026-05-16 18:32:57 2 [Note] WSREP: Non-primary view
mai 16 18:32:57 debianSQL1 mariadbd[801]: 2026-05-16 18:32:57 2 [Note] WSREP: Server status change connected -> connected
mai 16 18:32:57 debianSQL1 mariadbd[801]: 2026-05-16 18:32:57 2 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
mai 16 18:33:00 debianSQL1 mariadbd[801]: 2026-05-16 18:33:00 0 [Note] WSREP: (a381a02e-8bf8, 'tcp://0.0.0.0:4567') turning message relay req>
pascal@debianSQL1:~$
Ou notre console :
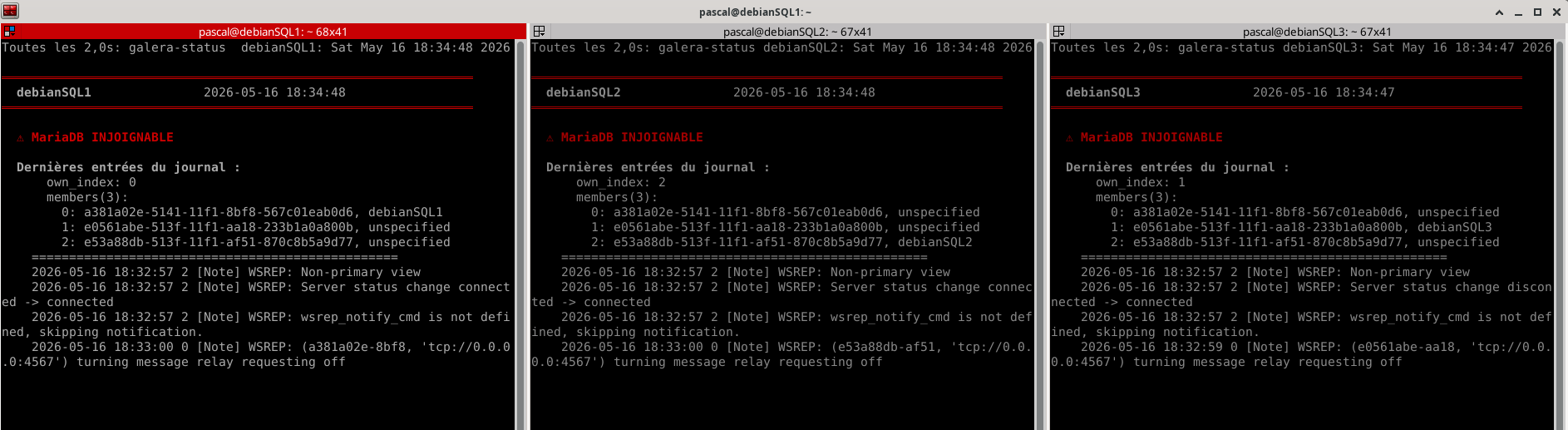
Pourquoi ? Aucun nœud ne sait s'il a les données les plus à jour. Chacun cherche les autres, ne les trouve pas, et refuse de bootstrapper de peur de partir avec un état périmé.
Il faut procéder à la récupération
¶ Procédure de récupération
- Identifier le nœud le plus à jour. Sur chaque nœud :
Comparer les valeurs desudo cat /var/lib/mysql/grastate.datseqno: le plus grand est le plus à jour.
Si le
seqnovalent-1, c'est que le nœud n'a fait un arrêt propre. Dans ce cas il faut faire unmysqld --wsrep-recoversur chaque nœud pour récupérer le dernier seqno enregistré dans le redo log. La procédure complète est documentée sur https://galeracluster.com/library/documentation/crash-recovery.html
Dans notre contexte, si les
seqnosont à-1, alors on choisit arbitrairement un noeud sur les trois.
-
Marquer ce nœud comme "safe to bootstrap" :
sudo nano /var/lib/mysql/grastate.datMettre
safe_to_bootstrap: 1. -
Bootstrapper le cluster depuis ce nœud uniquement :
sudo galera_new_cluster -
Vérifier que ça repart :
sudo systemctl status mariadb sudo mysql -u root -e "SHOW STATUS LIKE 'wsrep_cluster_size';" -
Démarrer les deux autres nœuds normalement :
sudo systemctl start mariadbIls rejoindront via IST ou SST.
¶ Bonus — Ajout d'un Galera Arbitrator (garbd)
Imaginons un contexte où on n'a budget que pour deux serveurs MariaDB (par exemple en multi-site avec deux DCs). Pour conserver le quorum sans payer un 3ème serveur de données, on utilise un Galera Arbitrator (garbd) sur une machine légère : il participe au vote pour le quorum mais ne stocke pas de données et ne reçoit pas les writesets en application (il les voit passer pour le vote, c'est tout).
Installons ce service sur un nouveau clone de debian Core
- hostname : debianGarbd
- ip : 192.168.1.14
¶ Installation
sudo apt update && sudo apt -y install galera-arbitrator-4
¶ Démarrage en mode interactif (pour observer)
sudo garbd -a gcomm://192.168.1.11,192.168.1.12,192.168.1.13 -g Galera_Cluster_PM
On voit les logs de connexion, l'établissement du lien avec les nœuds, et garbd qui devient un membre du cluster.
Depuis n'importe quel nœud Galera, vérifier :
SHOW STATUS LIKE 'wsrep_cluster_size';
Le résultat est désormais 4 : les 3 nœuds de données + garbd.
¶ Démonstration du gain de quorum
Avec garbd en place, on peut maintenant couper deux nœuds de données sans perdre le quorum (essayer les options du scénario 3)
Et vérifier que sur debianSQL1
SHOW STATUS LIKE 'wsrep_cluster_status';
on reste bien en mode Primary (alors qu'on serait passé en non-Primary sans garbd).
wsrep_cluster_size vaut maintenant 2 (debianSQL1 + garbd) — c'est suffisant pour le quorum sur un cluster initialement à 4 membres.
Les écritures continuent à fonctionner. C'est l'intérêt de garbd : maintenir le quorum à moindre coût.
¶ Configuration en service systemd (mode permanent)
Pour un usage durable, on configure garbd comme service :
sudo nano /etc/default/garb
Contenu :
GALERA_NODES="192.168.1.11:4567 192.168.1.12:4567 192.168.1.13:4567"
GALERA_GROUP="Galera_Cluster_PM"
LOG_FILE="/var/log/garbd.log"
sudo systemctl enable --now garbd
sudo systemctl status garbd
¶ Pour aller plus loin
Voici quelques pistes pour enrichir l'architecture en environnement de production :
- Chiffrement de la réplication : activer SSL/TLS entre les nœuds via
wsrep_provider_options="socket.ssl=YES;.... A imaginer uniquement si les nœuds sont sur des réseaux non maîtrisés. - Réseau dédié à la réplication : ajouter une 2ème interface réseau sur chaque nœud, dédiée au trafic Galera (port 4567), pour ne pas mélanger trafic client SQL et trafic de réplication.
- HAProxy en HA : ajouter Keepalived devant deux instances HAProxy pour éliminer le SPOF côté load balancer (cf. autres TPs).
- ProxySQL en remplacement de HAProxy : routage R/W automatique au niveau du protocole MySQL, connection pooling, query caching.
- Monitoring : intégrer les métriques wsrep dans Prometheus via
mysqld_exporter+ alertes surwsrep_cluster_size < 3,wsrep_local_recv_queue_avg > 100, etc. - Backups : Galera ne dispense pas de faire des backups. Un "malencontreux"
DROP DATABASEsera répliqué instantanément sur les 3 nœuds. Utilisermariabackuppour des sauvegardes régulières.
